In this Section we wil briefly explain the base principles of Automatic Speech Recognition(ASR).
A Speech recognizer is mainly made up of:
A set of acoustic models
A Language model
Acoustic models are the base bricks a Speech recognizer is made up of. They are mathematical models, and there is one for each elementary sound we want to recognize.
For example, in many ASRs, one model for each phoneme is built. These are the elementary sounds uttered words are made up of. Sometimes one model is built for each syllable. For example, we can have one model for a, another for b, c, or for pa, ca, sa etc.
We should not confuse alphabet letters with the phonemes alphabet: one alphabet letter could have more than one corresponding sound. For example, c can be pronounced as in cold or in cheap, thus it can have two corresponding models.
Acoustic models are trained on audio examples.
For example, the model for the a phoneme is trained by providing a large variety of recordings of “a” taken from a collection built in laboratory (corpus). Each “phonetic” model is able to recognize the related elementary sound. Generally speaking, an acoustic model calculates the probability that a piece of audio corresponds to the pieces in the training set. This probability is called likelihood.
The following figure resumes the work of an acoustic model.

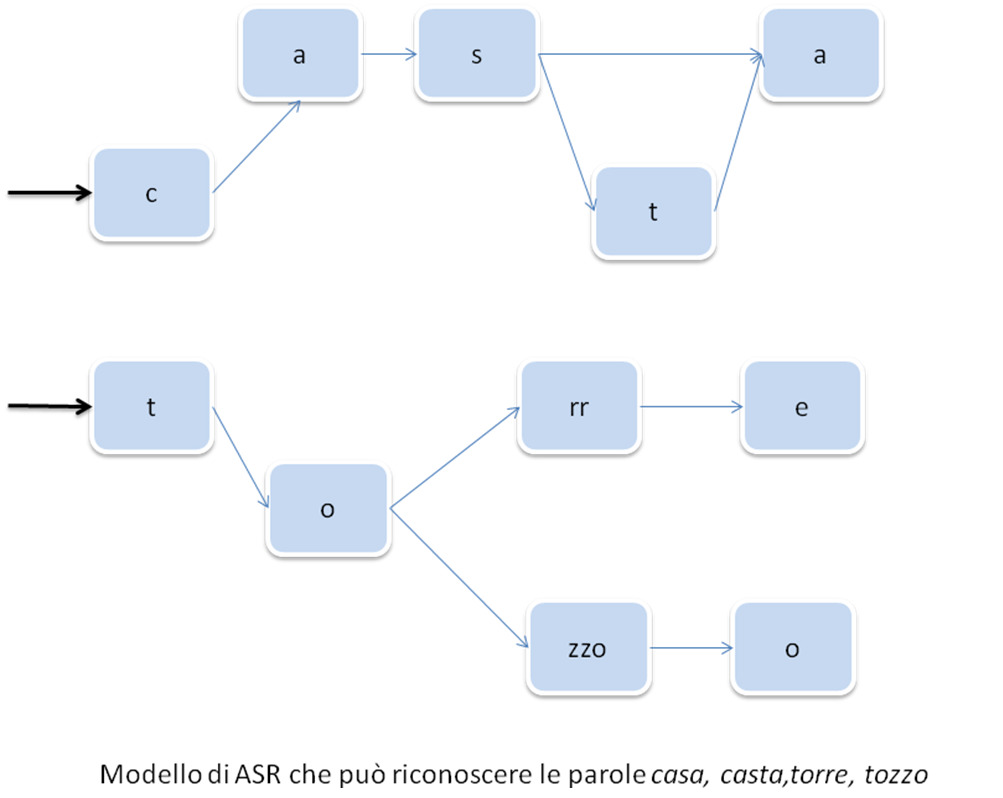
The language model indicates how the phonetic models shall be connected in order to build a word. It sets which words the ASR will be able to recognize and how these words are built as a sequence of connections between acoustic models.
Next figure shows this process.
When the ASR is asked to recognize an audio file, a decoding algorithm (the most used is the Viterbi algorithm) browses the language model, taking the acoustic models likelihoods into account at the same time.
The algorithm submits portions of audio to the models and collects the best probabilities obtained from the acoustic and language models together. The decoding algorithm reports the best sequence of acoustic models and consequently the uttered phrase.
Speaker Dependent vs Independent ASRs
GameMate is based on Speaker Independent Speech recognition technology. This means that the user has not to train the system with his/her voice. GameMate is in fact pre-trained using laboratory recordings on many voices.
Speaker Dependent Speech recognizers are the most used ones in dictation, but they require large training time to the user.
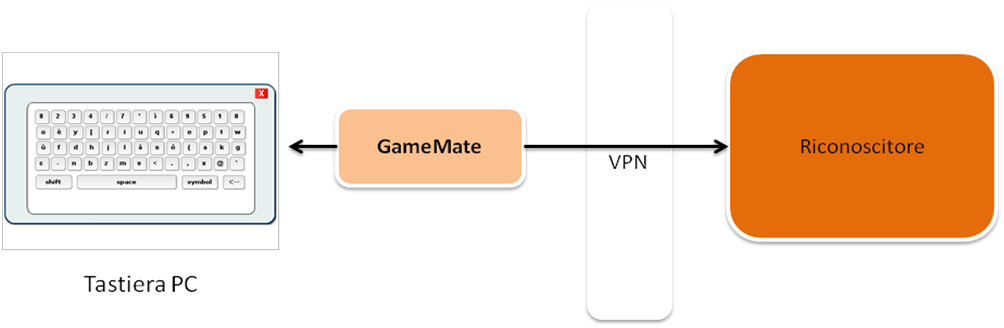
Game Mate Architecture for Videogames
GameMate is a standalone software. It does not require Internet connection, thus is it not prone to possible network interruptions.
Next figure shows a previous architecture of our software using a remote ASR. In the current version, the ASR is embedded in the GameMate.