In questa sezione spiegheremo brevemente i principi sui quali si basa il riconoscimento della voce (Automatic Speech Recognition o ASR). L’applicazione che ne presentiamo su questo sito è al campo dei videogiochi ma il discorso è del tutto generale.
Un riconoscitore vocale è costituito principalmente da:
Un insieme di modelli acustici
Un modello del linguaggio
I modelli acustici sono i mattoni elementari di cui si compone un riconoscitore. Si tratta di modelli matematici, ed in genere, ne esiste uno per ogni suono fondamentale che vogliamo riconoscere.
Ad esempio, in molti ASR, si costruisce un modello per ogni fonema (i suoni elementari di cui sono costituite le parole) o per ogni sillaba, per cui, si potrà avere un modello per la a, per la b, per la c, … oppure per pa, ca, sa,…eccetera.
Attenzione, non si confondano le lettere dell’alfabeto con i fonemi: ad una lettera dell’alfabeto può corrispondere anche più di un suono, ad esempio la c può essere pronunciata come in “casa” o in “cima”, quindi avrà due modelli corrispondenti.
I modelli acustici, prima del loro impiego nel riconoscimento di un segnale audio, vengono addestrati su esempi di audio, relativi alle unità loro corrispondenti.
Ad esempio il modello del fonema “a” viene addestrato mostrandogli una grossa varietà di “a” prese da una raccolta di file audio registrati in laboratorio. Ogni “mattone” ha quindi la capacità di riconoscere il suono elementale al quale è stato associato. In genere un modello acustico associa ad un pezzetto di audio, la probabilità che quest’ultimo sia il suono al quale il modello corrisponde, tale valore viene chiamato verosimiglianza.
La figura seguente riassume il funzionamento di un modello acustico.

Il modello del linguaggio è invece l’indicazione su come i vari “mattoni” devono essere messi insieme per formare le parole. Esso stabilisce quindi quali parole l’ASR potrà riconoscere e come queste parole possono essere costruite a partire dai modelli acustici.
La figura seguente mostra tale processo.
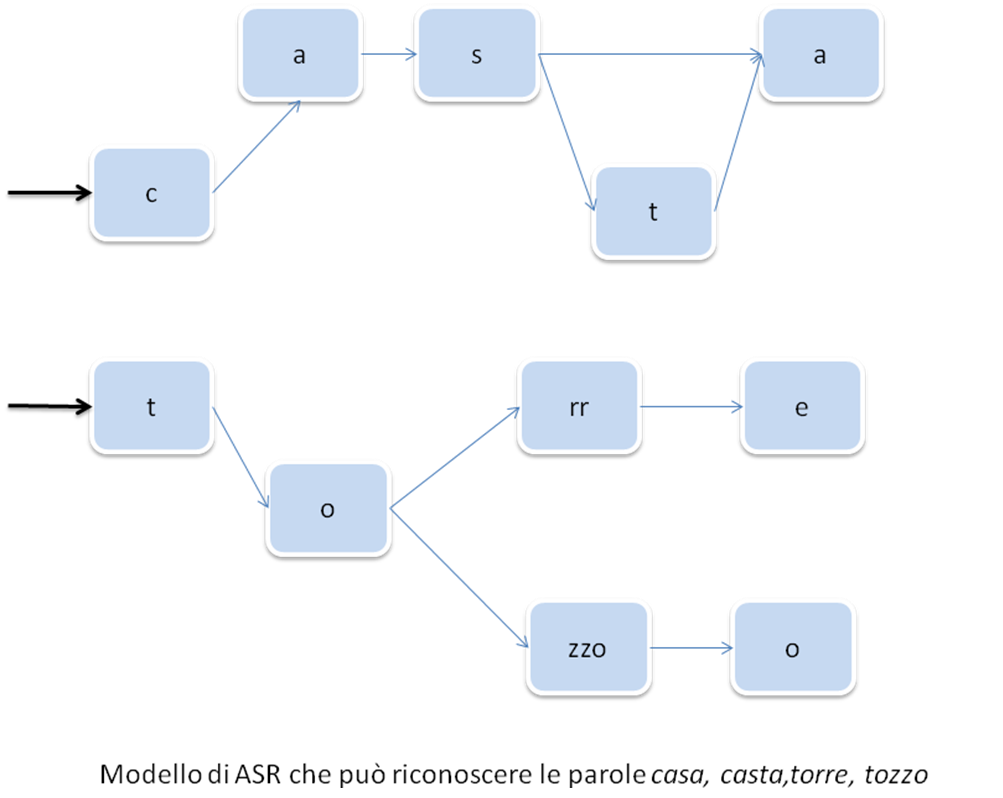
Nel momento in cui all’ASR viene sottoposto un audio da riconoscere, un algoritmo di decodifica (il più usato è quello di Viterbi) naviga il modello del linguaggio, tenendo conto contemporaneamente delle verosimiglianze che escono fuori dai modelli acustici.
L’algoritmo sottopone successioni di porzioni di audio ai modelli e tiene conto dei punteggi di verosimiglianza. Mettendo insieme i migliori punteggi ottenuti dai modelli e il modello del linguaggio, l’algoritmo di decodifica riesce ad ottenere la sequenza migliore di modelli acustici e di conseguenza la trascrizione della frase pronunciata.
Riconoscitori Speaker Dependent o Independent
Il GameMate si basa su tecnologia Speaker Independent. Ciò vuol dire che non viene richiesto all’utente di addestrare il sistema sulla propria voce, in quanto questo è già stato fatto su un enorme insieme di voci in laboratorio.
Gli Speaker Dependent sono i riconoscitori più diffusi, ad esempio nella dettatura automatica, ma richiedono una grossa perdita di tempo per l’addestramento.
Comandi Vocali e GameMate
I comandi vocali del GameMate corrispondono all’insieme di parole (vocabolario) riconoscibili dall’ASR. Il GameMate analizza tale insieme e divide le parole nei vari modelli acustici.
Contemporaneamente costruisce anche il modello del linguaggio che sancisce quali sequenze di parole possono essere pronunciate. Se ad ogni comando corrisponde solo una parola, il modello del linguaggio sarà molto semplice ed interesserà solo i legami tra modelli acustici intra-parola.
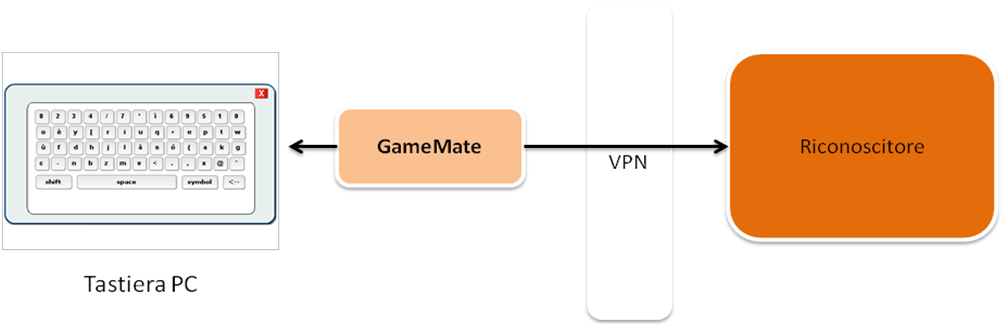
Architettura del Game Mate (GM) per i Videogame
Il GameMate richiede il collegamento ad un riconoscitore remoto. Ciò vuol dire che l’utente scarica sul suo PC un client, il quale si collegherà per lui al server remoto inviandogli l’audio.
L’AUDIO NON VIENE REGISTRATO IN ALCUN MODO SUL SERVER, per il rispetto della privacy e per il fatto che noi, unirenders, non siamo affatto interessati ad un tale genere di cose. Il client ha la funzione di generare il modello del linguaggio e i modelli acustici, a partire dalla configurazione locale del GM, e di schiacciare il tasto, o la combinazione, associata al comando pronunciato dall’utente.
In figura, una rappresentazione dell’architettura